有一天,当我正在浏览各种AI新闻时,我偶然看到了一个新的AI模型,名为MVDream。这个模型的目标很简单:通过一段文字来生成一个真实世界中的三维物体。听起来很神奇,对吧?但这真的是可能的!这让我想起了小时候,我们总是幻想能够只通过说话就创造出一个完整的物体。现在,MVDream正是在实现这个梦想。
从文字生成图像的技术已经非常成熟,但从文字生成高质量的3D模型则是一个全新的领域。MVDream不仅仅是一个初步尝试,它在这个方向上迈出了巨大的一步。
从文字到三维模型:MVDream的技术革命
与以往的尝试相比,MVDream显示出了对物理学的深入理解。例如,当给它输入“baby yoda in the style of Mormookiee”的文本时,它不会生成一个有四个耳朵的Yoda,因为它知道Yoda应该只有两个耳朵。这样的结果让人印象深刻。
但MVDream的真正魅力在于它的工作原理。在生成3D模型时,模型需要同时生成每一个角度的高质量图像,并确保这些图像在空间上是连贯的。过去的尝试往往只注重生成单个视角的图像,忽视了整体的三维结构。但MVDream不同,它解决了这个3D一致性问题。
该模型使用了一种名为“score distillation sampling”的技术,这是由DreamFusion提出的,我之前在频道上也有介绍过。这种技术可以确保生成的每个视角都是一致的,不会出现像以前那样的四耳朵Yoda。
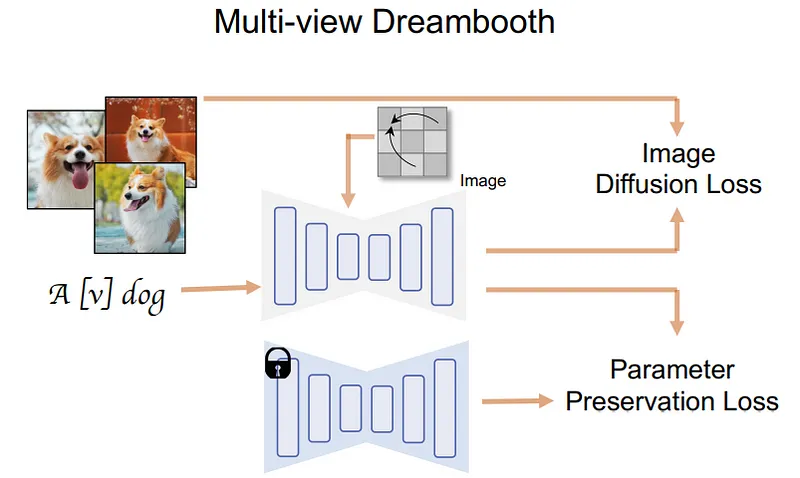
在了解这种技术之前,我们首先要了解MVDream使用的架构。简而言之,它是一个2D图像扩散模型,与DALLE、MidJourney或stable diffusion非常相似。具体来说,他们从一个预训练的DreamBooth模型开始,然后进行了一些修改,使其可以生成多视角的图像。
通过训练,该模型可以生成与输入的文本描述相符的物体的多个视角。然后,他们应用了多视角得分蒸馏采样过程。
他们现在拥有一个可以生成物体多个视角的模型,但他们希望这些视角能够重构为一致的3D模型。为此,他们使用了NeRF或神经辐射场。这个过程非常复杂,但关键是通过多次迭代来逐渐优化3D模型。
这就是MVDream如何从一个2D文字到图像模型,逐步改进为一个文字到3D模型的过程。当然,还有很多技术细节我并没有深入介绍,但如果你感兴趣,我非常推荐你去阅读他们的论文。
不过,这种新方法仍然有一些局限性。生成的图像分辨率只有256×256像素,虽然结果看起来令人惊叹,但分辨率仍然偏低。此外,用于这个任务的数据集大小对该方法的普遍性也是一个限制。
总之,MVDream为文字到3D模型的生成开辟了一条全新的道路。我非常期待看到更多关于这个模型的进展和应用。







