在本文中,我将深入探讨GeneFace++:一种新型的实时3D对话面孔生成技术。这项技术通过提高口型同步、视频真实感和系统效率,极大地推进了虚拟人视频合成领域。我将分享从环境准备到模型训练的全流程,让您能够有效利用这一技术。
GeneFace++:探索实时3D对话面孔生成的新纪元
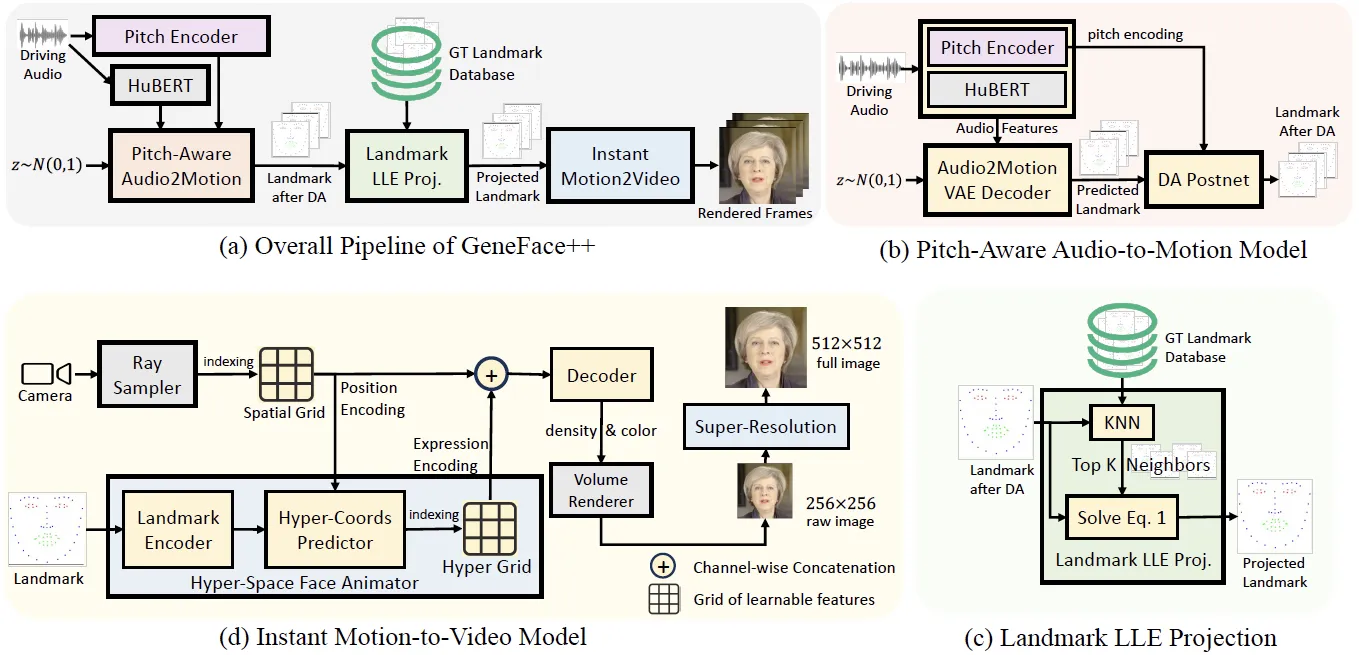
随着人工智能技术的快速发展,3D对话面孔生成技术在虚拟互动和数字媒体领域中的应用日益广泛。GeneFace++作为这一领域的新星,其官方PyTorch实现不仅提升了虚拟人视频合成的嘴形对齐、视频真实度和系统效率,还为研究人员和开发者提供了一个高效且可扩展的解决方案。
开始之前:环境准备与数据集配置
GeneFace++的实现依赖于精心准备的开发环境和数据。首先,您需要创建一个名为geneface的Python环境,并下载必要的3DMM文件来支持模型的3D映射和动作捕捉。接着,通过访问Google Drive或BaiduYun Disk,下载预处理的May数据集和预训练模型,这些是启动和运行GeneFace++的关键资料。
# 创建Python环境
conda create -n geneface python=3.8
conda activate geneface
# 下载并配置数据集
mkdir -p data/binary/videos/May
cd data/binary/videos/May
wget <your_download_link_for_trainval_dataset>快速上手:执行模型推断
配置好环境和数据后,您可以尝试运行以下命令来生成您的第一个虚拟人视频。此步骤将演示如何使用音频到动作模型(Audio2Motion)和动作到视频模型(Motion2Video)来合成视频。
export PYTHONPATH=./
python inference/genefacepp_infer.py --a2m_ckpt=checkpoints/audio2motion_vae --head_ckpt= --torso_ckpt=checkpoints/motion2video_nerf/may_torso --drv_aud=data/raw/val_wavs/MacronSpeech.wav --out_name=may_demo.mp4在这里,我们使用了Macron的演讲音频作为输入,通过GeneFace++技术生成了一个具有高度真实感的3D对话视频。这证明了GeneFace++不仅能够处理高质量的音视频生成,而且操作简便,易于上手。
自定义训练:在您自己的视频上应用GeneFace++
在您已经掌握如何使用预训练模型进行推断后,您可能会希望将GeneFace++应用到自己的视频项目中。以下是在您自己的目标人物视频上训练GeneFace++的步骤:
步骤1:数据预处理
为了训练GeneFace++模型,首先需要准备和处理您的视频数据。这包括视频的裁剪、格式转换以及面部特征的提取。GeneFace++ 提供了一系列工具和指导,帮助您标准化视频数据,以确保训练过程的顺利进行。
# 裁剪和转换视频
python tools/preprocess_video.py --input_video_path=<your_video_path> --output_dir=./data/preprocessed_videos
# 提取面部特征
python tools/extract_features.py --input_video_dir=./data/preprocessed_videos --output_dir=./data/features步骤2:训练模型
训练GeneFace++模型需要利用步骤1中处理好的视频数据。您可以通过调整训练参数来优化模型的表现,以更好地适应您的特定需求和视频样本。
# 启动训练过程
python train/train_genefacepp.py --data_dir=./data/features --output_dir=./checkpoints/my_model通过上述步骤,您不仅能够生成专门为您的视频优化的模型,还可以深入理解模型训练的每个细节,从而进行必要的调整和优化。
步骤3:评估和优化
训练完成后,评估模型的性能至关重要。您可以使用不同的度量标准来评估模型在口型同步、表情自然度以及视频真实感方面的表现。根据评估结果,您可能需要回到数据预处理或模型训练阶段进行调整,以达到更优的效果。
# 评估模型
python evaluate/evaluate_model.py --model_checkpoint=./checkpoints/my_model --eval_data_dir=./data/eval_data深入探讨GeneFace++的高级特性和应用案例
GeneFace++不仅为研究者和开发者提供了一个强大的工具,也拓展了3D对话面孔生成技术的应用范围。接下来,我们将探讨GeneFace++的几个高级特性以及如何在不同的应用场景中利用这些特性。
高级特性:实时性能优化
GeneFace++最引人注目的特点之一是其实时性能。通过优化的模型架构和高效的代码实现,GeneFace++能够在不牺牲输出质量的前提下,实现高速的数据处理和视频生成。这一特性使得GeneFace++特别适用于实时交互应用,如虚拟客服、在线教育和实时媒体演示。
# 实时视频生成示例代码
python realtime/genefacepp_realtime.py --model_checkpoint=./checkpoints/my_model --input_audio_stream=<your_live_audio_feed>应用案例:虚拟新闻主播
考虑到GeneFace++的高视频真实度和系统效率,它可以被用来创建虚拟新闻主播。这些虚拟主播能够根据实时新闻稿自动生成新闻报道视频,不仅提高了新闻发布的效率,也为媒体公司提供了一种成本效益高的内容创制方式。
应用案例:定制化视频内容创制
GeneFace++还可以应用于个性化视频内容的创制,如定制化的教育视频或个人化的广告。用户可以输入特定的文本或音频材料,GeneFace++将这些输入转化为具有高度个性化的视频内容,这对于增强用户体验和提高观看率具有显著效果。
结论
GeneFace++通过其先进的技术和灵活的应用可能性,正定义着未来的数字媒体和虚拟互动领域。无论是在业务扩展、教育创新还是媒体制作方面,GeneFace++都展示了巨大的潜力和价值。
通过本文的深入分析,我们不仅理解了GeneFace++的技术细节,还探索了其在各种实际应用中的广泛用途。希望这些信息能帮助您更好地利用这一技术,推动您的项目或研究向前发展。







