那天晚上,我的 IDE 里蹦出一行小字:“请选择默认模型”。
屏幕右下角的时钟显示 01:37,像是在提醒我,正常人这个点应该已经睡着,而不是在给一个叫 Claude Code Router 的东西配路由。
我盯着那几个选项:默认、后台、思考、长上下文。手里有一把牌——DeepSeek、Qwen3、各种 thinking 版、coder 版——但我根本不知道应该让谁上场。
就像踢球,队里都是球星,可是我连谁打前锋、谁去守门都没想明白。🤦♂️
于是我干脆问了下 AI:“你帮我排个阵容吧。”
接下来,你看到的这篇,就是那天凌晨的“排兵布阵笔记”。
一、IDE 里的“多模型人生”:为什么要路由?
如果你只用过一个模型,世界是简单的:
“无论什么问题,都问同一个家伙。”
但装上 Claude Code Router 之后,世界忽然复杂起来:
- 你可以接很多模型:DeepSeek、Qwen3、Gemini、OpenAI、OpenRouter……
-
每个模型都有自己的性格:
- 有的推理强,但贵;
- 有的便宜,但只适合同声传译;
- 有的记忆力爆棚,能记几本书;
- 有的只适合写点短代码。
Router 做的事其实很朴素:
把不同场景,分配给最合适的模型。
于是它在配置里给你准备了几个“角色”:
defaultbackgroundthinklongContextwebSearch- 再加一个
longContextThreshold
第一次见到这些,我的感觉是:
“你能不能像正常人一样写:主力、打杂、思想家、记性好的、爱上网的?”
不过这几个词背后,确实是有点讲究的。要把它们弄明白,后面的配置才不会乱。
二、先把“角色”看懂:default / background / think / longContext / webSearch
先别急着贴 config.json,我们先把这几个名字翻译成人话。😏
1. default:队里的前锋,也是你最常看的脸
什么时候用到?
- IDE 里写代码、改代码;
- 问报错、要解释;
- 写点注释、生成小工具函数;
- 聊天胡侃。
没有特别说明的时候,一切请求都会走
default。
该选什么样的模型?
- 综合能力最强;
- 代码、自然语言都靠谱;
- 不会一问三不知,也不会卡半天不说话。
你可以把 default 理解成:
“如果这个项目只能留一个模型,那就是它。”
2. background:后台搬砖工,干活多但不抢镜
什么时候用到?
-
在“背后默默干活”的任务:
- 多文件扫描;
- 批量重写;
- 预分析项目结构;
- 生成一些中间产物。
- 有些操作你点一个按钮,前台模型给你反馈,后台模型去跑长一点的分析。
所以 background 的模型,一般有这些特点:
- 便宜:因为调用频次会很高;
- 够用:不要求它写出世界上最优雅的代码,但别太离谱;
- 可以比 default 弱一点,但别弱太多。
一句话:
“能干体力活,别给我挖坑就行。”
3. think:认真思考的那一个,不适合用来点外卖
think 听着就有点装,但它确实是用来干重度推理的。
典型场景:
- 排查一个跨多模块的复杂 bug;
- 设计一套系统架构;
- 写一个需要很多推理步骤的算法;
- 分析边界情况、并发问题、事务一致性这些会让人掉头发的东西。
在这些场景里,你需要的不是“说人话的模型”,而是:
“愿意慢一点,但多动脑子”的模型。
所以 think 适合用:
- 那些名字里就带 reasoner / thinking / o3 之类后缀 的版本;
- 你愿意多付一点钱,换更稳妥的思考过程。
它不一定要当你的主力模型,但该它上场的时候,不能掉链子。
4. longContext:记性最好的人,负责应对“信息海啸”
如果你经常干这些事:
- 一次性丢几十个文件给模型;
- 让它读一整份产品文档、PRD、需求书;
- 扔给它几百 KB 的日志,让它自己想办法梳理。
那你就会发现:
有些模型聪明,但记忆力小;
有些模型不一定最聪明,但记忆力惊人。
longContext 的作用,就是当上下文长度超过阈值(longContextThreshold)时,Router 自动让这位“记性最好的人”顶上。
它的特点:
- 上下文窗口大(几十万 token 起步);
- 整体水平不错,但可能不如你的 default 那么尖锐;
- 适合干“耐心阅读大量资料,然后给个还行的答案”这种活。
你可以设一个阈值,比如 60000:
- 没超过,就继续用
default; - 超过了,就切到
longContext。
5. webSearch:那个爱上网的人
webSearch 一般和“联网搜索”“工具调用”相关。
有的模型:
- 自己就带搜索能力;
- 或者在你的框架里,专门被用来接第三方 API;
也有时候你可能只是懒得区分,干脆用和 default 一样的模型。
适合放在这里的模型:
- 对新信息、网页、搜索结果适应性好;
- 能看长文本网页,提取重点;
- 速度别太慢,不然你会怀疑自己是不是断网了。
如果暂时搞不清楚,就先和 default 设成一样,后面再单独优化。
6. 一张小表,看得更清楚一点
| 角色 | 触发时机 | 模型该有什么特点 | 举例场景 |
|---|---|---|---|
| default | 绝大部分普通请求 | 综合最强,代码&自然语言均衡 | 写代码、改代码、问报错、简单解释 |
| background | 后台任务、批处理 | 便宜、够用、稳定 | 扫描项目、预分析、多文件批量操作 |
| think | 需要深度推理、复杂决策时 | 推理能力强,允许稍慢、稍贵 | 复杂 bug、架构设计、算法、边界分析 |
| longContext | 上下文长度超过阈值时 | 上下文窗口巨大,阅读能力强 | 超长日志、整仓代码、长篇文档 |
| webSearch | 需要联网 / 调用外部信息时 | 善于处理搜索结果、网页 | 查资料、读 API 文档、看 news / issue |
看完这个表,你再回头看 Router 的配置项,多少就不那么抽象了。
三、把手上的牌排好:用 DeepSeek + Qwen 配一套阵容
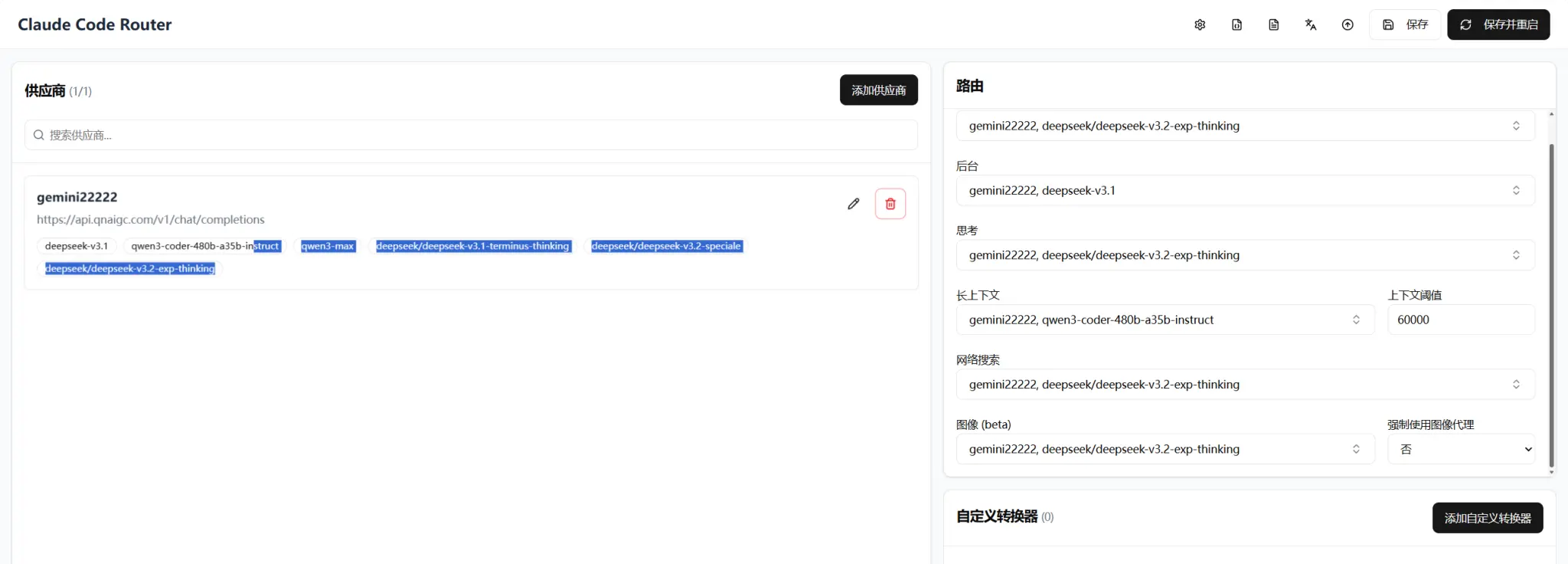
我们现在手里有一副真实牌,你的 provider 叫 gemini22222,接口是:
https://api.qnaigc.com/v1/chat/completions模型列表是:
deepseek-v3.1deepseek/deepseek-v3.1-terminus-thinkingdeepseek/deepseek-v3.2-specialedeepseek/deepseek-v3.2-exp-thinkingqwen3-maxqwen3-coder-480b-a35b-instruct
现在就像选足球阵容一样,我们一个位置一个位置来排。
1. default:让谁当主力?
候选人里,看名字就知道:
deepseek/deepseek-v3.2-speciale
——新版本,高配选手,适合做主力。deepseek-v3.1
——上一代主力,靠谱但略旧。qwen3-max
——综合模型,但你这套里还有 coder,适合做别的位置。
推荐:
default→gemini22222,deepseek/deepseek-v3.2-speciale
理由很简单:
写代码、日常聊天、解释问题,全部交给最强的那个,是最省心的选择。
2. background:找个能干活又不贵的
在你这套牌里,background 可以用:
deepseek-v3.1:已经证明过自己,性能足够;- 或者
qwen3-max:也 OK,但多留一个通用位给 webSearch 也不错。
我会这样选:
background→gemini22222,deepseek-v3.1
原因有三个:
- 对比 v3.2 high-end 版,v3.1 通常 更省钱;
- 写点辅助代码、做预分析完全没问题;
- 即便 background 暂时和 default实力有差距,对体验影响也不大,因为大多数你能直接看到的回复依然来自 default。
3. think:推理上限拉满
你手里有两个显眼的“thinking”类选手:
deepseek/deepseek-v3.1-terminus-thinkingdeepseek/deepseek-v3.2-exp-thinking
如果从“更新鲜 + 潜在能力更高”的角度,我会选:
think→gemini22222,deepseek/deepseek-v3.2-exp-thinking
把最强 reasoning 版本放到 think,能让下面这种场景变得舒服很多:
- “帮我彻底分析这个并发 bug,给出可能的 race 条件。”
- “这段业务流程所有分支路径帮我走一遍。”
- “给一个 3 个月的重构计划,把这个单体拆成服务。”
terminus-thinking 你也可以作为备选,或者在另一个环境单独配置做对比测试。
4. longContext:Qwen3 Coder 去守后场
长上下文的需求很明确:谁的记忆力大,就用谁。
在你的列表里,最适合当 longContext 的就是:
qwen3-coder-480b-a35b-instruct
光是名字里的 480b 就已经在拼命暗示你:
“我虽然贵一点,但我记得住的东西比别人多。”
所以这里的选择很自然:
longContext→gemini22222,qwen3-coder-480b-a35b-instruct
longContextThreshold→60000(可以先按默认来)
这么配的实际效果:
- 正常聊天 / 写代码:走
deepseek/deepseek-v3.2-speciale; - 偶尔扔点大文件:一开始还是 default,只要没超过阈值;
- 当对话历史 + 文件内容一起超过 6 万 token 时,Router 自动换成 Qwen3 Coder,把这场“信息海啸”扛下来。
5. webSearch:谁来负责上网?
对于 webSearch,你有两种思路:
-
简单粗暴版:
webSearch→ 和default一样 -
分工明确版:
webSearch→ 用qwen3-max,让它专门干查资料这类活
看你的模型组合,我会倾向第二种:
webSearch→gemini22222,qwen3-max
原因是:
- default 已经在忙着写代码;
- coder 版本已经去处理长上下文;
- 剩下这个
qwen3-max,刚好可以专门管理“读网页、查资料”。
当然,如果某天你发现 qwen3-max 的联网效果不如 deepseek 让你放心,你可以再把 webSearch 切回 deepseek/deepseek-v3.2-speciale,Router 配置改一下就完事。
6. 阵容一览表
下面这一表就相当于你的模型首发名单:
| Router 角色 | 绑定模型 | 人设定位 |
|---|---|---|
default |
gemini22222,deepseek/deepseek-v3.2-speciale |
主力前锋,绝大部分请求都靠它 |
background |
gemini22222,deepseek-v3.1 |
后台搬砖工,批处理、预分析 |
think |
gemini22222,deepseek/deepseek-v3.2-exp-thinking |
深度思考型选手,专管复杂推理 |
longContext |
gemini22222,qwen3-coder-480b-a35b-instruct |
记忆怪兽,负责超长上下文 |
longContextThreshold |
60000 |
超过 6 万 token 就切长上下文 |
webSearch |
gemini22222,qwen3-max |
爱上网的人,专管搜索与读网页 |
这个阵容已经足够支撑你在 IDE 里过得比大多数人更舒适了。😎
四、config.json 实战:从一行 URL 到完整路由
讲完“为什么”,该看看“怎么写”。
下面是一个简化版的 config.json 片段,专注在你这次要改的两个部分:Providers 和 Router。
1. Providers:先把所有牌摆到桌上
{
"Providers": [
{
"name": "gemini22222",
"api_base_url": "https://api.qnaigc.com/v1/chat/completions",
"api_key": "YOUR_API_KEY_HERE",
"models": [
"deepseek-v3.1",
"deepseek/deepseek-v3.1-terminus-thinking",
"deepseek/deepseek-v3.2-speciale",
"deepseek/deepseek-v3.2-exp-thinking",
"qwen3-max",
"qwen3-coder-480b-a35b-instruct"
],
"transformer": {
"use": [
"openai-compatible"
]
}
}
],
...
}这里有几个容易踩坑的点:
name必须和 Router 里写的一模一样,比如我们统一用gemini22222。-
models数组里的每一项:- 要和调用方支持的 model id 完全匹配;
- 不能自己随便改大小写、少写斜杠。
api_base_url用的是对方给的 chat completions 兼容地址。
只要 Provider 配对了,后面的路由才有意义。否则 Router 配得再优雅,也是对空气吼。
2. Router:给每个角色安排好“人选”
现在把前面那张“首发名单”翻译成真正的配置:
{
...
"Router": {
"default": "gemini22222,deepseek/deepseek-v3.2-speciale",
"background": "gemini22222,deepseek-v3.1",
"think": "gemini22222,deepseek/deepseek-v3.2-exp-thinking",
"longContext":"gemini22222,qwen3-coder-480b-a35b-instruct",
"longContextThreshold": 60000,
"webSearch": "gemini22222,qwen3-max"
}
}格式规则只有两条:
- 每个值都是一个字符串:
"providerName,modelId"; - 注意逗号左右可以有空格,也可以没有,但
providerName和modelId一定不能写错。
保存之后,通常你会:
- 关掉原来的服务;
- 再启动一次 Router(比如
ccr restart那套命令)。
IDE 里打开插件,看到每个路由下拉框对应的选项已经高亮,就是它开始按你写的阵容跑了。
3. 日常调参的几个小习惯
用久了之后,你大概率会遇到这些状况:
- “最近
default有点慢,是不是太忙了?” - “后台批处理好像也不需要那么强的模型?”
- “我这个项目里,超长上下文其实不多,用 coder 有点浪费。”
可以参考下面几个步骤来调:
-
先记录感受
- 是慢?贵?还是回答风格不满意?
-
对照 Router 角色
-
这个问题发生在哪种场景?
- 写代码时慢 → 看
default - 多文件处理慢 → 看
background - 超长任务卡死 → 看
longContext
- 写代码时慢 → 看
-
-
只改一个变量
- 比如:只把
background换成更便宜的模型; - 或者把
longContextThreshold从60000调到80000,让 default 多扛一点。
- 比如:只把
路由配置就像调球队阵容,
不要一次换 11 个人,
否则你都搞不清到底是谁踢得好。
4. 小结式备忘录(随手抄一份放旁边)
-
如果你懒得想很多:
default= 最强模型background= 稍微便宜一点的模型think= 带 thinking / reasoner 后缀的模型longContext= 上下文最大的模型webSearch= 一个你觉得“查资料够靠谱”的模型
-
如果你有 DeepSeek + Qwen 这套组合:
- default →
deepseek/deepseek-v3.2-speciale - background →
deepseek-v3.1 - think →
deepseek/deepseek-v3.2-exp-thinking - longContext →
qwen3-coder-480b-a35b-instruct+ 阈值 60000 - webSearch →
qwen3-max或和 default 一样
- default →
-
如果哪天又多接了几个模型:
- 先想清楚它适合当哪个“角色”;
- 再把 Router 里对应的那一行换掉;
- 重启服务,看实际体验。
那天凌晨配置完路由,我关掉 IDE,才发现窗外已经泛起一点亮光。
对于绝大多数人来说,这只是几个模型名字的排列组合;
但对天天和代码打交道的人来说,它决定了以后每一次敲下快捷键时,屏幕那头到底是谁在回答你。
至于谁更懂你写的那堆 bug,谁更适合当你深夜的搭档——
现在你至少有能力,亲手给他们排个座位。✨







